So much data, so little money

Data pipelines on a budget
It has become a cliché to state that you never need to worry about performance or scale in a startup. After all, you’re not Google yet, right?
True, but you don’t have their resources either. And not every startup creates a simple workflow app, with few interactions and no real data processing to speak of.
When you’re on a budget and on a tight schedule, but still need to engineer a dependable data pipeline, what are your options?
Of course, there’s more than one way to skin a cat, and I’m not suggesting our choices are better than others. But they have yielded good results so far, so this exploration can serve as a basis for reflexion should you face similar challenges.
Our context
AdAlong makes content from social networks easily searchable and groupable, thanks to a combination of computer vision label extraction and the use of a search engine.
Each day, at AdAlong, we process a few dozens of GB of media data. We:
- collect it from various social networks, such as Instagram and Twitter
- apply computer vision / deep learning algorithms to extract visual information
- run a few data transform operations on metadata, such as language detection
- ingest this data into Elasticsearch
Also, we need to have cheap backups and a way to easily reload them.
Finally, our data processing is largely linear.
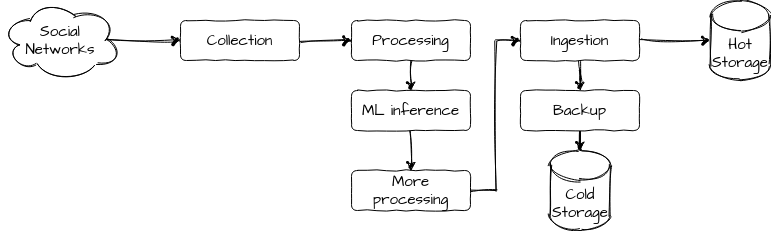
Crucially, we are only five developers in the engineering team, and our platform has been serving customers for 2 years.
Sounds familiar? Let’s explore our options!
The simplistic database-driven workflow
When you start a project as a single database-backed monolith, and want to keep it this way for as long as possible (say, until you get some traction), it is very tempting to use the database to orchestrate your data processing.
One way of doing it is to save records to be processed, together with data processing information (either embedded in the same document or linked with a foreign key). Records will then pass from one processing stage to another, either by way of a cron job of some sort or (god forbid) database or ORM triggers.
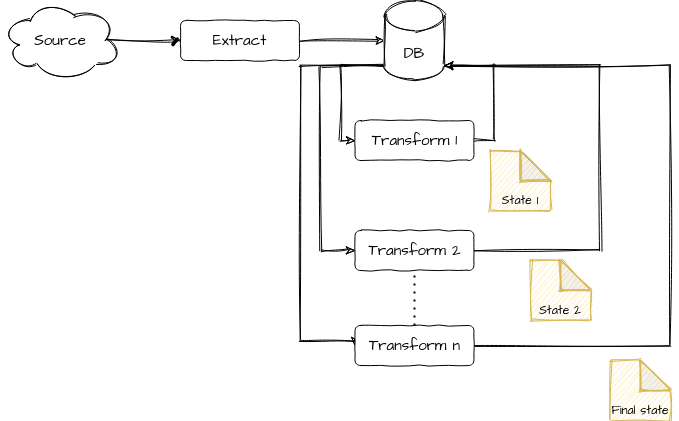
The issues with this approach are fairly obvious:
- At ingestion time, you are stressing your database, particularly if you are processing your records one by one via triggers, while keeping the indexing process running. I once had to deal with an Active Record Callbacks-based data pipeline in Ruby on Rails, and wasn’t really impressed with the throughput, as you can imagine.
- You are typically altering your records during processing. This makes reprocessing, and generally going back in time, impossible. If you want to keep different versions of the same records, then storage can become expensive in a hot database.
Nonetheless, because it was the simplest approach, we went for it during AdAlong’s early days, ingesting unprocessed records, together with processing metadata, directly into Mongo. A cron job would then promote records from one state to another. As expected, beyond a certain scale, the database was put under too much pressure and we had to find another way.
The Enterprise™ Big Data® Toolsets
Spark! Hadoop! Dataproc! Beam! Flink! Airflow!
The list of data processing frameworks and tools with bold performance claims and questionable logos is (or was) ever-growing. Startups with no real experience in data engineering might be tempted to take the red pill and learn one or more of the aforementioned. After all, a tool dedicated to the very task at hand must be a safe bet right?

Wrong! Here are a few reasons why this can be a terrible choice for startups that want to stay nimble:
- These frameworks are typically complex and require proper team training if you don’t want your team cargo-culting endlessly on Stackoverflow when something goes wrong. Not to mention learning new languages in some cases (e.g. Scala for Spark — I know you can do without in theory, but it’s still the preferred approach).
- They are resource-heavy, especially the HDFS-based ones, which require replication, coordination overhead, serialization, etc. If you don’t really need tens of nodes to distribute your workload to, you can’t really amortize this overhead.
The sweet spot
We found that a sweet spot for us was a combination of:
- Dependable data processing infrastructure run by cloud providers, with clear semantics. We tried to push as much of the error handling and retry logic as possible in it.
- Simple custom programs that are easy to operate and debug, perform idempotent operations, and are generally OK to kill without warning.
The event bus
Since we operate our stack on Google Cloud Platform, we based our pipeline on Google Pub/Sub’s infrastructure. It’s a Google operated, auto-scalable event bus, that supports multiple subscriptions, retries on failure with exponential back-off, and retention of consumed messages.
The data processors
Our processing is spread across various executables that consume from and produce data to Pub/Sub. These executables live inside a Google-operated Kubernetes cluster, and as such can easily be scaled, killed, replaced, and otherwise operated in an easy, uniform and well-documented way.
They are mostly written in Go, which produces fairly low-footprint, fast to boot binaries, well-suited for running in Kubernetes. The learning curve is also somewhat flat compared to alternatives and non-experts can quickly contribute.
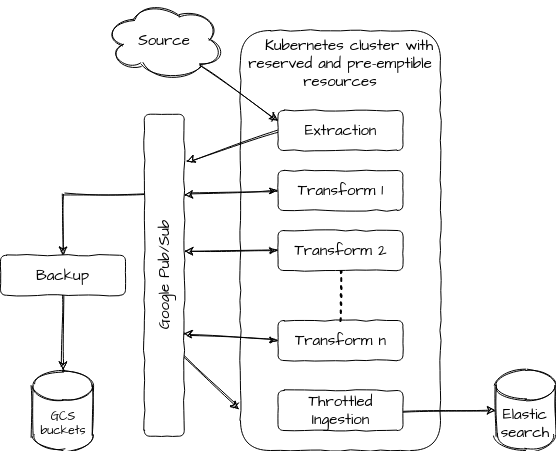
The combo
This combination has worked well for us, particularly in these scenarii:
- Bursts: Pub/Sub provides a 7-days buffer that leaves us plenty of time to scale our ingestion in case of spike. In our case, it’s especially useful for expensive ML operations, for which we have a dedicated, auto-scalable pool of preemptible nodes. While we accumulate new records rapidly in our event bus, our pool can scale up when nodes are available and scale down when we don’t have any records left in our backlog. This makes for a very cheap processing strategy, since preemptible nodes are around one-third the cost of on-demand nodes, and they only operate when needed.
- Smooth ingestion: it’s important to control the ingestion rate to our destination database (in this case: Elasticsearch) to prevent service degradation for our users. We faced this issue with the “simplistic database-driven workflow” strategy we saw earlier. With a Pub/Sub buffer between the upstream and our destination database, we can make sure that we ingest data at a controlled rate.
- Error handling: If a processing component crashes, outstanding records simply accumulate in front of it while we scramble to repair it. In less dramatic cases, such as a few records failing, they stay in the subscription queue and are replayed with an exponential backoff delay, leaving us some time to fix our component or trash the offending record.
- Deployment: Because we have many small executables performing idempotent operations, it’s trivial to deploy new versions of them without having to think too hard about graceful shutdown or draining strategies. We just kill them unceremoniously, and their replacements will continue the work pretty much where their predecessors left off.
- Cost: Because we use simple Go programs with not much overhead such as auxiliary DBs, Zookeepers, master nodes, slave nodes and whatnot, the processing power we need is very low, which is a must to keep our operational margin high.
Limitation
Of course the Enterprise™ Big Data® Toolsets exist for a reason! We don’t face such problems as:
- Windowing or sessionization
- Distributed joins requiring shuffling
- Real-time processing, though our architecture is well-suited for this need
- Conversions between a zoo of data formats: ORC, parquet, arrow, avro and so on.
But even then, careful need analysis and alternative options exploration would be essential before jumping into the Big Data abyss.
Conclusion
While going for a full-blown data processing solution might be required for you, it might take time before you face the need and have the resources to justify it.
You might well stay for a long time in a situation where the simplistic data processing workflow strategy won’t cut it anymore, if not straight endanger your business because of its short-comings.
In this case, a combination of simple, understandable programs running on top of a commodity, dependable infrastructure might be your best bet.